
by Todd McDonald and first published on Moz.com.
A steady rise in content-related marketing disciplines and an increasing connection between effective SEO and content has made the benefits of harnessing strategic content clearer than ever. However, success isn’t always easy. It’s often quite difficult, as I’m sure many of you know.
A number of challenges must be overcome for success to be realized from end-to-end, and finding quick ways to keep your content ideas fresh and relevant is invaluable. To help with this facet of developing strategic content, I’ve laid out a process below that shows how a few SEO tools and a little creativity can help you identify content ideas based on actual conversations your audience is having online.
What you’ll need
Screaming Frog: The first thing you’ll need is a copy of Screaming Frog (SF) and a license. Fortunately, it isn’t expensive (around $150/USD for a year) and there are a number of tutorials if you aren’t familiar with the program. After you’ve downloaded and set it up, you’re ready to get to work.
Google AdWords Account: Most of you will have access to an AdWords account due to actually running ads through it. If you aren’t active with the AdWords system, you can still create an account and use the tools for free, although the process has gotten more annoying over the years.
Excel/Google Drive (Sheets): Either one will do. You’ll need something to work with the data outside of SF.
Browser: We walk through the examples below utilizing Chrome.
The concept
One way to gather ideas for content is to aggregate data on what your target audience is talking about. There are a number of ways to do this, including utilizing search data, but it lags behind real-time social discussions, and the various tools we have at our disposal as SEOs rarely show the full picture without A LOT of monkey business. In some situations, determining intent can be tricky and require further digging and research. On the flipside, gathering information on social conversations isn’t necessarily that quick either (Twitter threads, Facebook discussion, etc.), and many tools that have been built to enhance this process are cost-prohibitive.
But what if you could efficiently uncover hundreds of specific topics, long-tail queries, questions, and more that your audience is talking about, and you could do it in around 20 minutes of focused work? That would be sweet, right? Well, it can be done by using SF to crawl discussions that your audience is having online in forums, on blogs, Q&A sites, and more.
Still here? Good, let’s do this.
The process
Step 1 – Identifying targets
The first thing you’ll need to do is identify locations where your ideal audience is discussing topics related to your industry. While you may already have a good sense of where these places are, expanding your list or identifying sites that match well with specific segments of your audience can be very valuable. In order to complete this task, I’ll utilize Google’s Display Planner. For the purposes of this article, I’ll walk through this process for a pretend content-driven site in the Home and Garden vertical.
Please note, searches within Google or other search engines can also be a helpful part of this process, especially if you’re familiar with advanced operators and can identify platforms with obvious signatures that sites in your vertical often use for community areas. WordPress and vBulletin are examples of that.
Google’s Display Planner
Before getting started, I want to note I won’t be going deep on how to use the Display Planner for the sake of time, and because there are a number of resources covering the topic. I highly suggest some background reading if you’re not familiar with it, or at least do some brief hands-on experimenting.
I’ll start by looking for options in Google’s Display Planner by entering keywords related to my website and the topics of interest to my audience. I’ll use the single word “gardening.” In the screenshot below, I’ve selected “individual targeting ideas” from the menu mid-page, and then “sites.” This allows me to see specific sites the system believes match well with my targeting parameters.

I’ll then select a top result to see a variety of information tied to the site, including demographics and main topics. Notice that I could refine my search results further by utilizing the filters on the left side of the screen under “Campaign Targeting.” For now, I’m happy with my results and won’t bother adjusting these.
Step 2 – Setting up Screaming Frog
Next, I’ll take the website URL and open it in Chrome.
Once on the site, I need to first confirm that there’s a portion of the site where discussion is taking place. Typically, you’ll be looking for forums, message boards, comment sections on articles or blog posts, etc. Essentially, any place where users are interacting can work, depending on your goals.
In this case, I’m in luck. My first target has a “Gardening Questions” section that’s essentially a message board.

A quick look at a few of the thread names shows a variety of questions being asked and a good number of threads to work with. The specific parameters around this are up to you — just a simple judgment call.
Now for the fun part — time to fire up Screaming Frog!
I’ll utilize the “Custom Extraction” feature found here:
Configuration → Custom → Extraction
…within SF (you can find more details and broader use-case documentation set for this feature here). Utilizing Custom Extraction will allow me to grab specific text (or other elements) off of a set of pages.
Configuring extraction parameters
I’ll start by configuring the extraction parameters.

In this shot I’ve opened the custom extraction settings and have set the first extractor to XPath. I need multiple extractors set up, because multiple thread titles on the same URL need to be grabbed. You can simply cut and paste the code into the next extractors — but be sure to update the number sequence (outlined in orange) at the end to avoid grabbing the same information over and over.
Notice as well, I’ve set the extraction type to “extract text.” This is typically the cleanest way to grab the information needed, although experimentation with the other options may be required if you’re having trouble getting the data you need.
Tip: As you work on this, you might find you need to grab different parts of the HTML than what you thought. This process of getting things dialed can take some trial-and-error (more on this below).
Grabbing Xpath code
To grab the actual extraction code we need (visible in the middle box above):
- Use Chrome
- Navigate to a URL with the content you want to capture
- Right-click on the text you’d like to grab and select “inspect” or “inspect element”

Make sure you see the text you want highlighted in the code view, then right-click and select “XPath” (you can use other options, but I recommend reviewing the SF documentation mentioned above first).

It’s worth noting that many times, when you’re trying to grab the XPath for the text you want, you’ll actually need to select the HTML element one level above the text selected in the front-end view of the website (step three above).
At this point, it’s not a bad idea to run a very brief test crawl to make sure the desired information is being pulled. To do this:
- Start the crawler on the URL of the page where the XPath information was copied from
- Stop the crawler after about 10–15 seconds and navigate to the “custom” tab of SF, set the filter to “extraction” (or something different if you adjusted naming in some way), and look for data in the extractor fields (scroll right). If this is done right, I’ll see the text I wanted to grab next to one of the first URLs crawled. Bingo.
 Resolving extraction issues & controlling the crawl
Resolving extraction issues & controlling the crawl
Everything looks good in my example, on the surface. What you’ll likely notice, however, is that there are other URLs listed without extraction text. This can happen when the code is slightly different on certain pages, or SF moves on to other site sections. I have a few options to resolve this issue:
- Crawl other batches of pages separately walking through this same process, but with adjusted XPath code taken from one of the other URLs.
- Switch to using regex or another option besides XPath to help broaden parameters and potentially capture the information I’m after on other pages.
- Ignore the pages altogether and exclude them from the crawl.
In this situation, I’m going to exclude the pages I can’t pull information from based on my current settings and lock SF into the content we want. This may be another point of experimentation, but it doesn’t take much experience for you to get a feel for the direction you’ll want to go if the problem arises.
In order to lock SF to URLs I would like data from, I’ll use the “include” and “exclude” options under the “configuration” menu item. I’ll start with include options.

Here, I can configure SF to only crawl specific URLs on the site using regex. In this case, what’s needed is fairly simple — I just want to include anything in the /questions/ subfolder, which is where I originally found the content I want to scrape. One parameter is all that’s required, and it happens to match the example given within SF ☺:
The “excludes” are where things get slightly (but only slightly) trickier.
During the initial crawl, I took note of a number of URLs that SF was not extracting information from. In this instance, these pages are neatly tucked into various subfolders. This makes exclusion easy as long as I can find and appropriately define them.

In order to cut these folders out, I’ll add the following lines to the exclude filter:
Upon further testing, I discovered I needed to exclude the following folders as well:
It’s worth noting that you don’t HAVE to work through this part of configuring SF to get the data you want. If SF is let loose, it will crawl everything within the start folder, which would also include the data I want. The refinements above are far more efficient from a crawl perspective and also lessen the chance I’ll be a pest to the site. It’s good to play nice.
Completed crawl & extraction example
Here’s how things look now that I’ve got the crawl dialed:
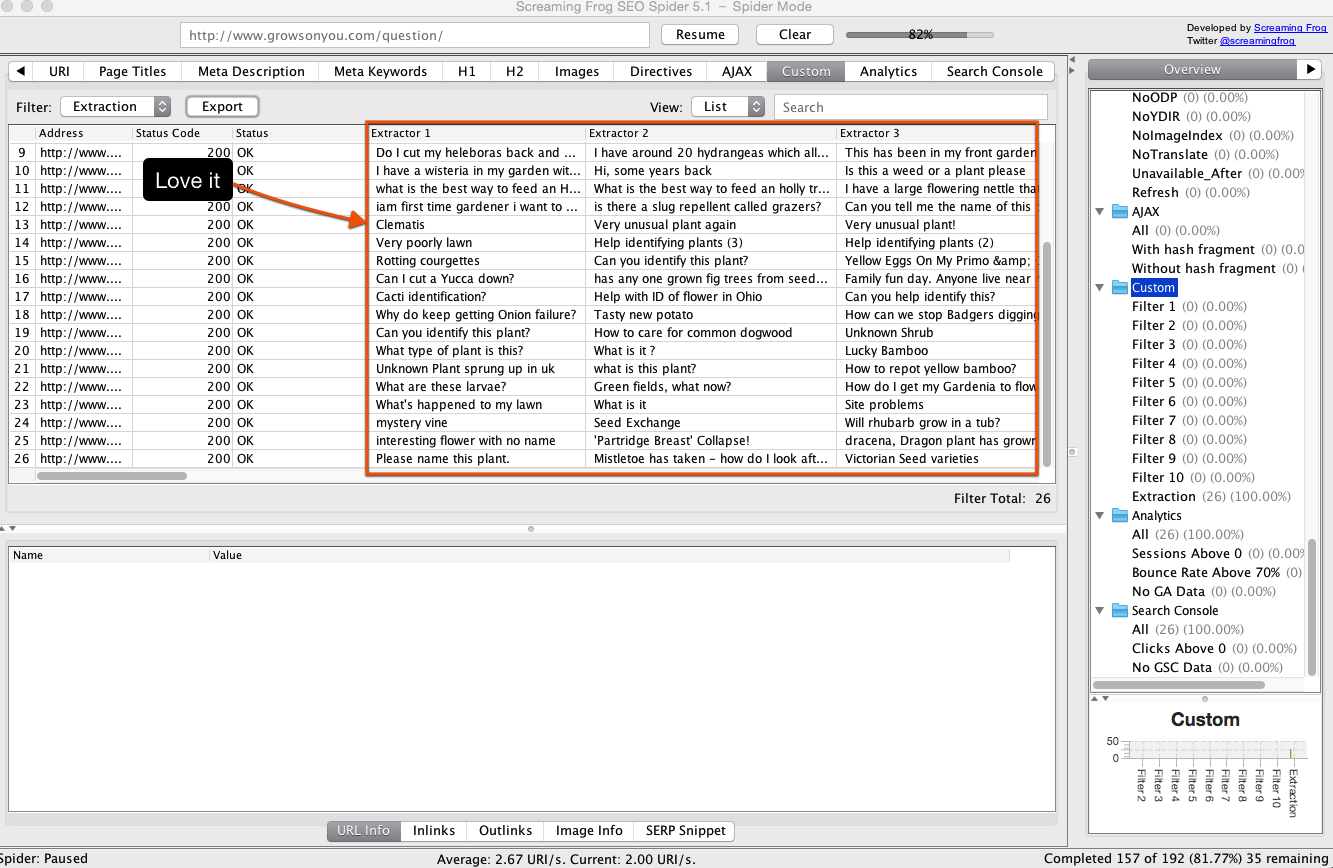
Now I’m 99.9% good to go! The last crawl configuration is to reduce speed to avoid negatively impacting the website (or getting throttled). This can easily be done by going to Configuration → Speed and reducing the number of threads and URIs that can be crawled. I usually stick with something at or under 5 threads and 2 URIs.
Step 3 – Ideas for analyzing data
After the end goal is reached (run time, URIs crawled, etc.) it’s time to stop the crawl and move on to data analysis. There a number of ways to start breaking apart the information grabbed that can be helpful, but for now I’ll walk through one approach with a couple of variations.
Identifying popular words and phrases
My objective is to help generate content ideas and identify words and phrases that my target audience is using in a social setting. To do that, I’ll use a couple of simple tools to help me break apart my information:
The top two URLs perform text analysis, with some of you possibly already familiar with the basic word-cloud generating abilities of tagcrowd.com. Online-Utility won’t pump out pretty visuals, but it provides a helpful breakout of common 2- to 8-word phrases, as well as occurrence counts on individual words. There are many tools that perform these functions; find the ones you like best if these don’t work!
I’ll start with Tagcrowd.com.
Utilizing Tagcrowd for analysis
The first thing I need to do is export a .csv of the data scraped from SF and combine all the extractor data columns into one. I can then remove blank rows, and after that scrub my data a little. Typically, I remove things like:
- Punctuation
- Extra spaces (the Excel “trim” function often works well)
- Odd characters
Now that I’ve got a clean data set free of extra characters and odd spaces, I’ll copy the column and paste it into a plain text editor to remove formatting. I often use the one online at editpad.org.
That leaves me with this:

In Editpad, you can easily copy your clean data and paste it into the entry box on Tagcrowd. Once you’ve done that, hit visualize and you’re there.
Tagcrowd.com

There are a few settings down below that can be edited in Tagcrowd, such as minimum word occurrence, similar word grouping, etc. I typically utilize a minimum word occurrence of 2, so that I have some level of frequency and cut out clutter, which I’ve used for this example. You may set a higher threshold depending on how many words you want to look at.
For my example, I’ve highlighted a few items in the cloud that are somewhat informational.
Clearly, there’s a fair amount of discussion around “flowers,” seeds,” and the words “identify” and “ID.” While I have no doubt my gardening sample site is already discussing most of these major topics such as flowers, seeds, and trees, perhaps they haven’t realized how common questions are around identification. This one item could lead to a world of new content ideas.
In my example, I didn’t crawl my sample site very deeply and thus my data was fairly limited. Deeper crawling will yield more interesting results, and you’ve likely realized already how in this example, crawling during various seasons could highlight topics and issues that are currently important to gardeners.
It’s also interesting that the word “please” shows up. Many would probably ignore this, but to me, it’s likely a subtle signal about the communication style of the target market I’m dealing with. This is polite and friendly language that I’m willing to bet would not show up on message boards and forums in many other verticals ☺. Often, the greatest insights besides understanding popular topics from this type of study are related to a better understanding of communication style, phrasing, and more that your audience uses. All of this information can help you craft your strategy for connection, content, and outreach.
Utilizing Online-Utility.org for analysis
Since I’ve already scrubbed and prepared my data for Tagcrowd, I can paste it into the Online-Utility entry box and hit “process text.”
After doing this, we ended up with this output:


There’s more information available, but for the sake of space, I’ve grabbed only a couple of shots to give you the idea of most of what you’ll see.
Notice in the first image, the phrases “identify this plant” & “what is this” both show up multiple times in the content I grabbed, further supporting the likelihood that content developed around plant identification is a good idea and something that seems to be in demand.
Utilizing Excel for analysis
Let’s take a quick look at one other method for analyzing my data.
One of the simplest ways to digest the information is in Excel. After scrubbing the data and combining it into one column, a simple A→Z sort, puts the information in a format that helps bring patterns to light.

Here, I can see a list of specific questions ripe for content development! This type of information, combined with data from tools such as keywordtool.io, can help identify and capture long-tail search traffic and topics of interest that would otherwise be hidden.
Tip: Extracting information this way sets you up for very simple promotion opportunities. If you build great content that answers one of these questions, go share it back at the site you crawled! There’s nothing spammy about providing a good answer with a link to more information if the content you’ve developed is truly an asset.
It’s also worth noting that since this site was discovered through the Display Planner, I already have demographic information on the folks who are likely posting these questions. I could also do more research on who is interested in this brand (and likely posting this type of content) utilizing the powerful ad tools at Facebook.
This information allows me to quickly connect demographics with content ideas and keywords.
While intent has proven to be very powerful and will sometimes outweigh misaligned messaging, it’s always great to know as much about who you’re talking to and be able to cater messaging to them.
Wrapping it up
This is just the beginning and it’s important to understand that.
The real power of this process lies in its usage of simple, affordable, tools to gain information efficiently — making it accessible to many on your team, and an easy sell to those that hold the purse strings no matter your organization size. This process is affordable for mid-size and small businesses, and is far less likely to result in waiting on larger purchases for those at the enterprise level.
What information is gathered and how it is analyzed can vary wildly, even within my stated objective of generating content ideas. All of it can be right. The variations on this method are numerous and allow for creative problem solvers and thinkers to easily gather data that can bring them great insight into their audiences’ wants, needs, psychographics, demographics, and more.
Be creative and happy crawling!


