Written by Larry Kim, founder of WordStream.

Let’s start with the bad news first. It’s tougher than ever to get content noticed.
Changes to Google search results pages have further obscured content organically, especially on competitive commercial searches. Meanwhile, paid search costs per click (CPCs) are at all-time highs in established markets.
Organic reach in social media? It’s pretty much dead. Half of all content gets zero shares, and less than 0.1 percent is shared more than 1,000 times.
Additionally, the typical internet marketing conversion rate is less than one percent.

How Content Marketing Doesn’t (Usually) Work
How does content marketing actually work? Many people’s content marketing strategy basically consists of a three-step process:
- Create new content.
- Share your content on social networks (Facebook, Twitter, LinkedIn, etc.).
- People buy your stuff.
Nope. This almost never happens. (For a content marketing strategy that actually works, try a documented plan such as the Content Marketing Pyramid™.)
Most content goes nowhere. The consumer purchase journey isn’t a straight line—and it takes time.

So is there a more reliable way to increase leads and sales with content?
Social Media Advertising To The Rescue!

Now it’s time for the good news! Social media advertising provides the most scalable content promotion and is proven to turn visitors into leads and customers.
And the best part? You don’t need a huge ad budget.
A better, more realistic process for content marketing with promotion looks like this:
- Create: Produce content and share it on social media.
- Amplify: Selectively promote your top content on social media.
- Tag: Build your remarketing audience by tagging site visitors with a cookie.
- Filter: Apply behavioral and demographic filters on your audience.
- Remarketing: Remarket to your audience with display ads, social ads, and Remarketing Lists for Search Ads (RLSA) to promote offers.
- Convert: Capture qualified leads or sale.
- Repeat.
Promotion is sorely overlooked from many content marketers’ priority list—it’s actually the lowest priority according to a recent study of 1000+ marketers. For marketers who take promotion more seriously, The Ultimate List of Content Promotion Tools is a godsend.
You can use the following ten Twitter and Facebook advertising hacks as a catalyst to get more eyeballs on your content, or as an accelerant to create an even larger traffic explosion.
1. Improve Your Quality Score
Quality Score is the metric Google uses to rate the quality and relevance of your keywords and PPC ads, and influences your cost-per-click. Facebook calls their version a “Relevancy Score”:

While Twitter’s is called a “Quality Adjusted Bid”:

Whatever it’s called, Quality Score is a crucial metric. The way to increase Twitter and Facebook Quality Scores is to increase post engagement rates.
A high Quality Score is great: you get a higher ad impression share for the same budget at a lower cost per engagement. On the flip side, a low Quality Score sucks: you get a low ad impression share and a high cost per engagement.
How do you increase engagement rates? Promote your best content—your unicorns (the top 1-3 percent of content that performs better than everything else) rather than your donkeys (the bottom 97 percent of your content).
To figure out if your content is a unicorn or donkey, test it out.

- Post lots of stuff (organically) to Twitter and use Twitter Analytics to see which content gets the most engagement.
- Post your top stuff from Twitter organically to LinkedIn and Facebook. Again, track which posts get the most traction.
- Pay to promote the unicorns on Facebook and Twitter.
The key to paid social media advertising is to be picky. Cast a narrow net and maximize those engagement rates.
2. Increase Engagement With Audience Targeting

Targeting all your fans isn’t precise; it’s lazy and wastes a lot of money.
Your fans aren’t a homogenous blob. They all have different incomes, interests, values, and preferences.
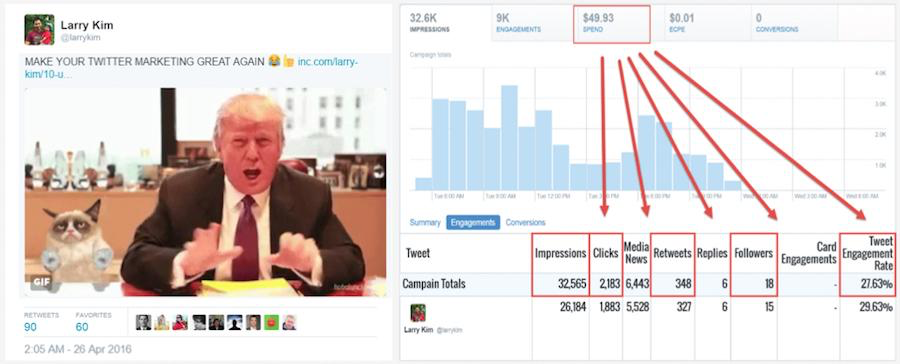
For example, by targeting fans of Donald Trump, people with social media marketing job titles, NRA members, and the hashtag #NeverHillary (and excluding Democrats, fans of Hillary Clinton, and the hashtag #neverTrump), this tweet for an Inc. article I wrote got ten times higher engagement:

Keyword targeting and other audience targeting methods helps turn average ads into unicorns.
3. Generate Free Clicks From Paid Social Media Advertising
On Twitter, tweet engagements are the most popular type of ad campaign. Why? I have no idea. You have to pay for every user engagement (whether someone views your profile, expands your image, expands your tweet from the tweet stream, or clicks on a hashtag).
If you’re doing this, you need to stop—now. It’s a giant waste of money and offers the worst ROI.
Instead, pay only for the thing that matters most to your business, whether it’s clicks to your website, app installs, followers, leads, or actual video views.
For example, when you run a Twitter followers campaign, you pay only when someone follows you. But your tweet promoting one of your unicorn pieces of content will also get a ton of impressions, retweets, replies, mentions, likes, and visits to your website. All for the low, low cost of $0.
4. Promote Unicorn Video Ads!
Would you believe you can get thousands of video views at a cost of just $0.02 per view?

Shoppers who view videos are more likely to remember you, and buy from you. Quick tips for success:
- Promote videos that have performed the best (i.e., driven the most engagement) on your website, YouTube, or elsewhere.
- Make sure people can understand your video without hearing it— an amazing 85 percent of Facebook videos are watched without sound, according to Digiday.
- Make it memorable, try to keep it short, and target the right audience.
Bonus: video ad campaigns increase relevancy score by two points!
5. Score Huge Wins With Custom Audiences
True story: a while back I wrote an article asking: Do Twitter Ads Work? To promote the article on Twitter, I used their tailored audiences feature to target key influencers.
The very same day, Business Insider asked for permission to publish the story. So I promoted that version of the article to influencers using tailored audiences.
An hour later, a Fox News producer emailed me. Look where I found myself:

The awesome power of custom audiences resulted in additional live interviews with major news outlets including the BBC; 250 high-value press pickups and links, massive brand exposure, 100,000 visits to the WordStream site, and a new business relationship with Facebook.
This is just one example of identity-based marketing using social media advertising. Whether it’s Twitter’s tailored audiences or Facebook’s custom audiences, this opens a ton of new and exciting advertising use cases!
6. Promote Your Content On More Social Platforms
Medium, Hacker News, Reddit, Digg, and LinkedIn Pulse all send you massive amounts of traffic. It’s important to post content to each that’s appropriate to the audience.
Post content on Medium or LinkedIn. New content is fine, but repurposing existing content is a better strategy because it gives a whole new audience the chance to discover and consume your existing content.
Again, use social media advertising as either a catalyst or an accelerant to get hundreds, thousands, or even millions of views you otherwise wouldn’t have. It might even open you up to syndication opportunities—I’ve had posts syndicated to New York Observer and Time Magazine.
You can also promote existing content on sites like Hacker News, Reddit, or Digg. Getting upvotes can create valuable exposure that sends tons of traffic to your existing content.
For a minimal investment, you can get serious exposure and traffic!
7. Hacking RankBrain for Insanely Awesome SEO
Google is using an AI machine learning system called RankBrain to understand and interpret long-tail queries, especially on queries Google has never seen before—an estimated 15 percent of all queries.
I believe Google is examining user engagement metrics (such as click-through rates, bounce rates, dwell time, and conversion rates) as a way—in part, to rank pages that have earned very few or no links.

Even if user engagement metrics aren’t part of the core ranking algorithm, getting really high organic CTRs and conversion rates has its own great rewards:
- More clicks and conversions.
- Better organic search rankings.
- Even more clicks and conversions.

For example, research found a 19 percent lift in paid search conversion volume and a 10 percent improvement in cost per action (CPA) with exposure to Facebook ads for the financial services company Experian.
Use social media advertising to build brand recognition and double your organic search clickthrough and conversion rates!
8. Social Media Remarketing
Social media remarketing, on average, boosts engagement by three times and doubles conversion rates, while cutting your costs by a third. Make the most of it!
Use social media remarketing to push your hard offers, such as sign-ups, consultations, and downloads.
9. Combine Everything With Super Remarketing

Super remarketing is the awesome combination of remarketing, demographics, behaviors, and high engagement content. Here’s how and why it works.
- Behavior and interest targeting: These are the people interested in your stuff.
- Remarketing: These are the people who have recently checked out your stuff.
- Demographic targeting: These are the people who can afford to buy your stuff.
If you target paid social media advertising to a narrow audience that meets all three criteria using your high engagement unicorns—the result?

10. Combine Paid Search & Social Media Advertising
For our final, and most advanced hack of them all, we combine social media advertising with PPC search ads on Google using Remarketing Lists for Search Ads (RLSA).
RLSA is incredibly powerful. You can target customized search ads specifically to people who have recently visited your site when they search on Google. It increases click-through and conversion rates by three times and reduces cost-per-click by a third.
There’s one problem. By definition, RLSA doesn’t target people who are unfamiliar with your brand. This is where social media advertising comes in: it helps more people become familiar with your brand.
Social media advertising is a cheap way to start the process of biasing people towards you. While they may not need what you’re selling now, later, when the need arises, people are much more likely to do a branded search for your stuff, or click on you during an unbranded search because they remember your compelling content.

If your content marketing efforts are struggling, these ridiculously powerful Twitter and Facebook advertising hacks will turn your content donkeys into unicorns! Looking for another awesome hack to supercharge your content ROI? Social curation enables more consistent content publication, supports your created content strategy, and helps you keep track of your favorite information. Download The Ultimate Guide to Content Curation eBook.